Data Serialization: How Protocol Buffers Achieve Efficiency
I am a backend developer with interests in distributed systems, database internals and software architecture.
In the world of distributed systems and microservices, we often want to communicate with different services hosted on different servers in various geographical locations. To do this, we need to serialize the payload (in-memory structure to bytes) at the sender's end and send it over the network. Then it's deserialized (bytes to in-memory structure) at the receiver's end. We want to make this process as fast and efficient as possible. So how can we achieve this, and what are our options?
Using language-specific serialization format: Say both the services were written in Golang; in that case, we could use something like gob to encode and decode the data. But this is unnecessarily restrictive as we are committing to using that language everywhere, which isn’t practical.
JSON: JSON is widely popular, and almost all languages and browsers support it. But it has a few problems:
- It doesn’t support binary strings.
- It doesn’t have efficient encoding and takes up a lot of space.
- It also has issues dealing with numbers.
To overcome the above shortcomings, we can use Protocol buffer, a language-neutral, platform-neutral mechanism for serializing structured data. It's schema-based and efficient, making it ideal for inter-server communications and archival storage of data on disk.
But how does Protocol buffer encode the data efficiently? Let’s have a peek under the hood and figure out how it works and how it fares compared to JSON.
Protocol buffer vs JSON :
For our little experiment, we’ll create the same structure in JSON and Protobuf, then compare the serialized bytes with each other and figure out how exactly Protobuf achieves its efficiency.
In order to work with Protocol buffer, we’ll have to create messages described in .proto files. Then the proto compiler is invoked at build time on .proto files to generate code in our required programming language (Golang) to manipulate the corresponding protocol buffer. Each generated class contains simple accessors for each field and methods to serialize and parse the whole structure to and from raw bytes.
# Protobuf schema
syntax = "proto3";
option go_package = "github.com/Calvinsd/go-proto/model";
message Person {
string Name = 1;
int32 Age = 2;
}
Here we've defined a simple schema with a message person that has two fields: name of type string and age of type int32. (You can refer this doc for the list of types).
Now we’ll write a simple Golang script to initialize and serialize the Protobuf message and also a similar JSON message and compare their serialized bytes size.
import (
"encoding/json"
"fmt"
"log"
// importing the generated model by proto compiler
"github.com/Calvinsd/go-proto/model"
"google.golang.org/protobuf/proto"
)
// JSON message struct
type PersonJson struct {
Name string `json:"Name"`
Age int32 `json:"Age"`
}
func main() {
// JSON Message
jsonPerson := PersonJson{
"Newton",
150,
}
// Protobuf message
protoPerson := model.Person{
Name: "Newton",
Age: 150,
}
// serializing json
serializedJson, err := json.Marshal(jsonPerson)
if err != nil {
log.Fatal(err)
}
// serializing protobuf
serializedProto, err := proto.Marshal(&protoPerson)
if err != nil {
log.Fatal(err)
}
fmt.Println("Serialized json length", len(serializedJson))
fmt.Println("Serialized proto length", len(serializedProto))
}
The above code prints the following message :

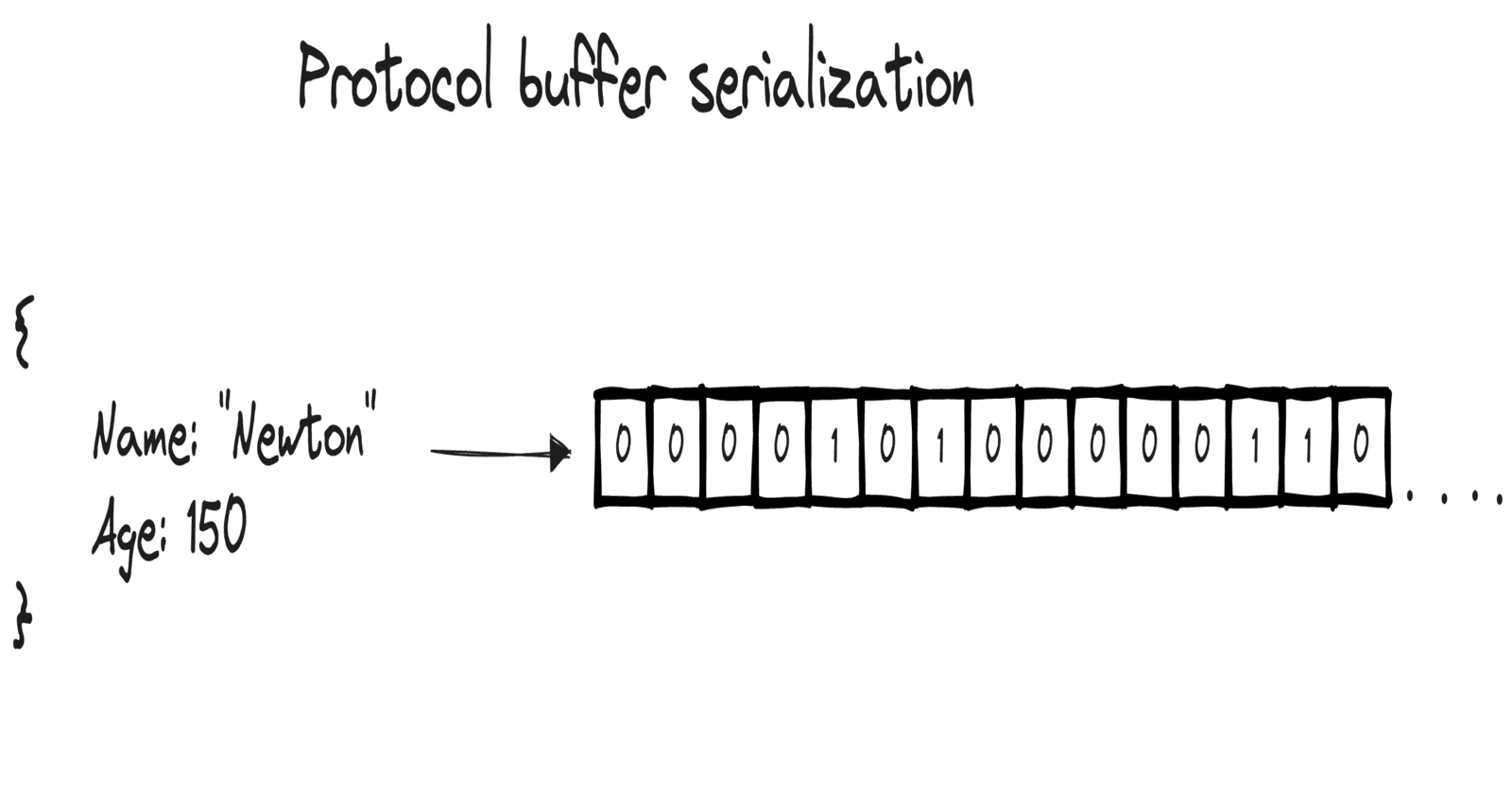
We can see that JSON takes up 27 bytes while Protobuf incredibly takes up only 11 bytes which is way less than JSON. But how does it do it?
Firstly JSON: each character in JSON is encoded using a single byte, so if you count the number of characters in the JSON it counts to 27.
{"Name":"calvin","Age":150}
NOTE: Numbers are encoded as a sequence of digits, so each digit takes up 1 byte.
Now let's look at Protobuf and how it encodes the same data in just 11 bytes.

Above are the 11 bytes sequentially laid out in binary and decimal format. But they don't make much sense to us yet so let's decode it.
Message structure in binary:
VARINT:
Variable-width integers, or varints, are at the core of the wire format(how message is sent over wire). They allow encoding unsigned 64-bit integers using only as many bytes as required.
Each byte in the varint has a continuation bit that indicates if the byte that follows it is part of the varint. This is the most significant bit (MSB) of the byte (sometimes also called the sign bit). The lower 7 bits are a payload; the resulting integer is built by appending together the 7-bit payloads of its constituent bytes.
Tag :
The “tag” of a record is encoded as a varint formed from the field number and the wire type.
To decode this first we'll have to decode the varint representing a field, the lower 3 bits tell us the wire type, and the rest of the integer tells us the field number.
INFO:
There are six wire types:VARINT : 0,I64 : 1,LEN : 2,SGROUP : 3,EGROUP : 4, andI32 : 5.
Each message in Protobuf is a series of key-value pair, the binary version of the message just uses tag(encoded as varint) to replace the key when a message is encoded, by not saving the field name and just using the tag(field number and wire type) it saves a few bytes.
Each key-value pair is turned into a record consisting of the field number, a wire type and a payload. The wire type tells the parser how big the payload is and if the wire type is of type LEN the next byte after the tag is a varint representing the length of the payload. This type of schema is called TAG-LENGTH-VALUE (TLV).
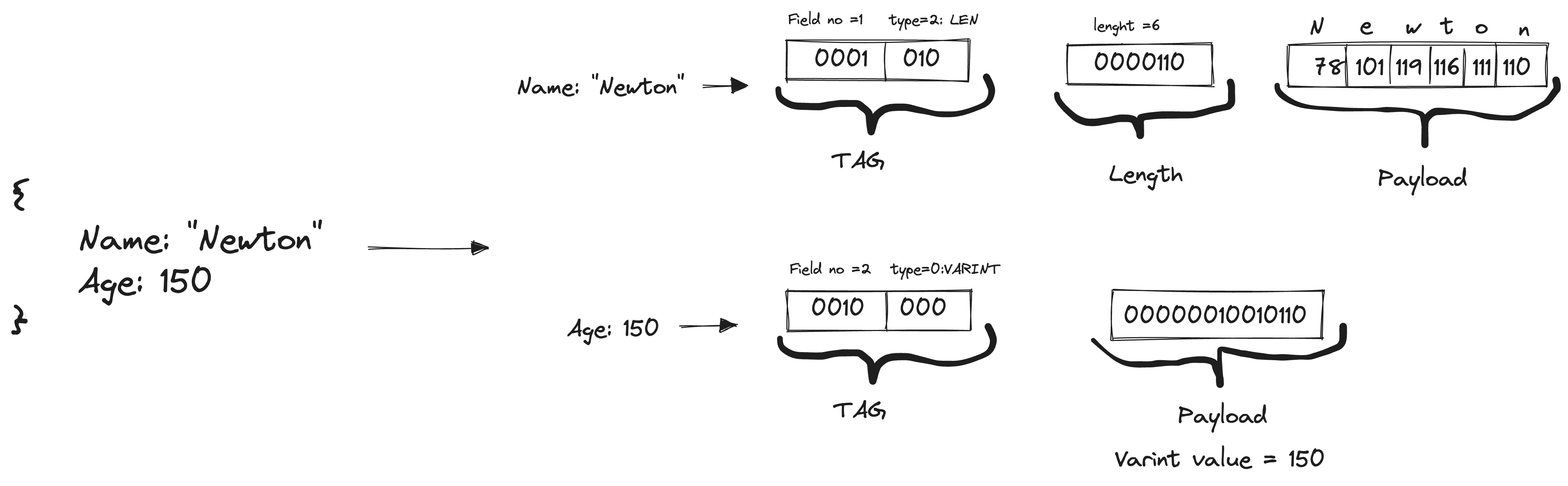
Decoding the serialized message:
The first key-value pair in our case is the Name field with field number 1 of type string with data "Newton".
So the first byte of the encoded data is the tag, and we can decode the tag from the serialized bytes:
// 1st byte
00001010 // MSB of 0 indicates no continuation, so remove MSB
0001 010 // first 4 bits indicate field number as 1
// last 3 bits indicate wire type as 2 i.e LEN
As the wire type is LEN the payload has dynamic length, specified by a varint immediately after the tag, which is followed by the payload as usual.
So the next byte with value 6 signifies the length of the payload.
And the following 6 bytes are payload, which is nothing but ASCII characters for "Newton" = "N":78, "e":101, "w":119, "t":116, "o":111, "n":110.
This completes our first key-value pair.
We repeat the same process for the next key-value pair.
We start by decoding the tag:
// 9th byte
00010000 // MSB of 0 indicates no continuation, remove MSB
0010 000 // first 4 bits indicate field number as 2
// last 3 bits indicate wire type as 0 i.e VARINT
So we get the field number as 2 and the payload of type VARINT.
Now we can decode the payload; the next byte, which is a varint, has its MSB set to 1, which indicates continuation, so we have to consider the following byte as well, which has its MSB set to 0, marking no more continuation.
// 10th and 11th byte
10010110 00000001 // inputs
0010110 0000001 // Dropping MSB/coninuation bit
0000001 0010110 // converting to big endian, as protbuf encodes byte order in little endian
00000010010110 // concatinate
128 + 16 + 4 + 2 = 150 // so the value is 150
Post decoding we get the value of 150.
Final view of the deserialized data:
Epilogue:
In the world of distributed systems, the efficiency of data serialization is crucial. Protocol buffers, as explored in this post, stand out for their compact and efficient encoding, offering a significant advantage over traditional methods like JSON. By leveraging varints, tags, and wire types, they achieve faster transmission and reduced storage requirements. This innovation not only underscores the importance of thoughtful data handling but also highlights the potential for creative solutions in the quest for performance and efficiency in technology. There are a few more optimizations that Protocol buffer does which are not discussed in this post you can read more in detail about it here also the code used above is available here.