Logs in Distributed Systems: A Guide
I am a backend developer with interests in distributed systems, database internals and software architecture.
Introduction:
A few years ago, logs had a simple meaning to me: data written to standard output on the terminal or a file to monitor an application and assist in debugging in case of a crash. This definition of logs was confined to mostly human-readable application logs. Although essential, this view of logs was limited.
So what are logs in distributed systems?
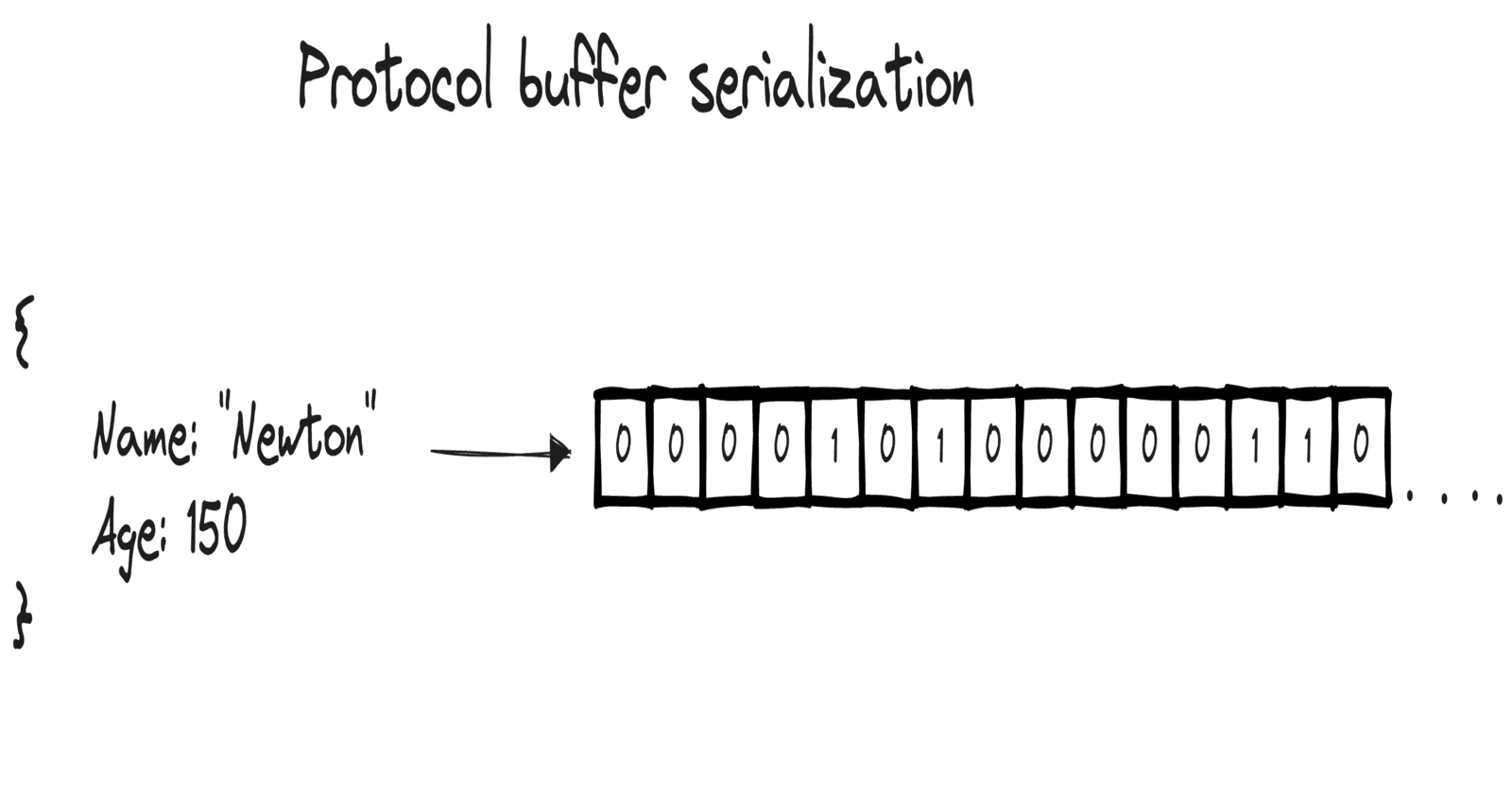
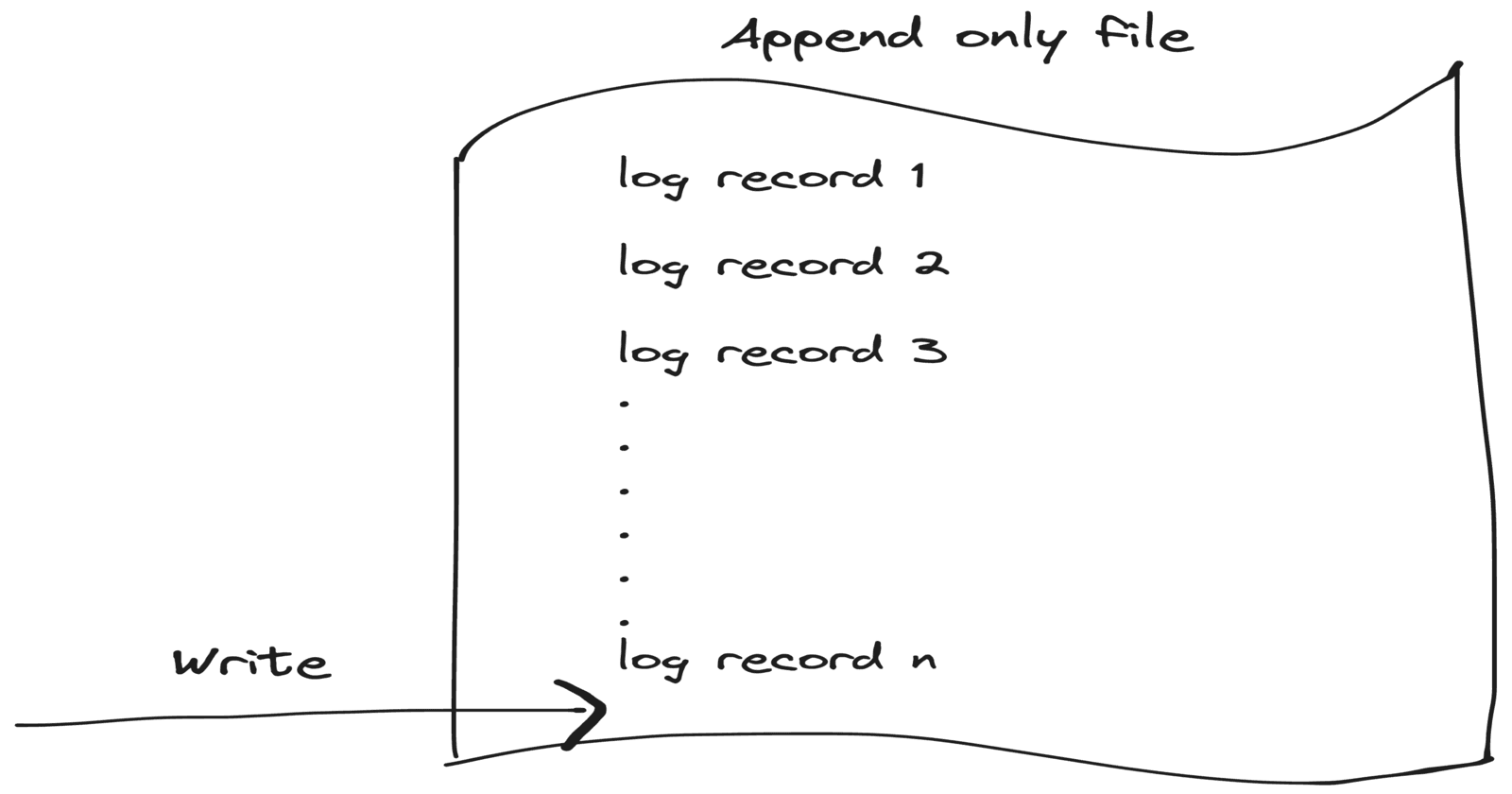
In the context of distributed and data systems, logs are an append-only sequence of records written to a file, ordered by time, often in a non-human-readable format, and sometimes compressed for better performance. These simple yet powerful append-only files allow an easy way to record an ordered sequence of immutable records and store them reliably. Now, let's explore how these logs are utilized in distributed systems.
WAL (Write Ahead Log):
WAL stands for Write-Ahead Logging. It is a technique used in database systems to ensure that transactions are handled with integrity, even when system failures occur.
When writing to a database, the data might be stored temporarily in RAM or cache before being flushed to disk at a later point. To avoid losing data when a system crashes in between this process a write-ahead log is used. The idea is that changes are first written to a log an append-only file persistent on disk before they are applied to the actual database.
WAL provides durability by ensuring that any changes requested to a database are written first to the WAL and ensure that if the server storing the data crashes, it should still complete the action on restart and not lose any data.
WAL provides the following advantages
Crash recovery: If a system crash occurs, the WAL can be used to recover the database by reapplying the logged changes.
Increased Durability: As changes are written to a log before being applied to the database, the system can ensure that committed transactions are preserved even if a failure occurs immediately afterward.
Performance Improvements: By writing sequentially to the log file rather than making multiple random writes to the database, WAL can improve write performance in some cases.
Also flushing data from RAM to disk can be done periodically and not necessarily on every write as WAL can protect from intermediate failures, hence impoving performance.
Database Replication:
Replication is the process of copying and maintaining database objects, in multiple locations to improve data availability, accessibility, and performance. To copy and synchronize the data from a primary node (master)where the write has happened to the remaining nodes is done by maintaining a replication log which maintains a sequential record of all changes made to the database. The replication log is then sent to replica databases to sync the data. This can be done in real time (synchronous ) or with a delay (asynchronous).
Advantages of Replication:
High Availability: If one replica fails, others are available to take over.
Load distribution: Read and write operations can be distributed across replicas.
Fault Tolerance: Replication protects against hardware failure and data loss.
Improved Performance: Geographically distributed replicas can reduce latency for end-users.
Event sourcing:
Event sourcing captures all changes to an application state as sequence of events. This is achieved by persisting the state of a business entity as a sequence of state-changing events. Whenever the state of a business entity changes, a new event is appended to the list of events. To get the current state of the entity we can replay the list of events in sequence to reconstruct it.
The recorded series of events are stored in an append-only log preserving their order. The log is typically stored in a durable and fault-tolerant manner, ensuring that events are not lost even in the face of system failures.
Advantages of event sourcing:
Reconstructing state: We can discard and reconstruct the application state at any moment by replaying the events.
Viewing history: We can view the application state at any point in time by replaying the events up to that particular point.
Atomic: Saving an event is a single operation, hence it is inherently atomic.
Event-driven architecture: Event Sourcing naturally fits with event-driven architectures, enabling easy integration and communication between different parts of a distributed system.
Log-based message brokers:
Log-based message brokers are different from traditional message brokers. In Traditional message brokers data is written to the queue by the producer and once the consumer processes and acknowledges the data is deleted from the queue. But in log-based message brokers the data is written to an append-only log on disk maintaining the order and making it durable, this allows multiple clients to consume the same event at different points in time as reading the data from the file does not remove the data.
Advantages of log-based message brokers:
Durability: As data is persisted on disk it is durable, ensuring that data can be recovered after failure.
Ordered data: Data is written to an append-only file hence order is maintained.
Event-Driven Architectures: They form the backbone of event-driven systems, where changes in state are captured as events and propagated through the system via the broker.
Stream Processing: Log-based brokers are fundamental for real-time stream processing, enabling the processing of live data streams.
Epilogue:
Logs, although often understated, are central to modern-day distributed systems. From ensuring data integrity with Write-Ahead Logging to enhancing system resilience through log-based message brokers, logs are fundamental building blocks. Their simplicity and effectiveness will continue to make them an indispensable tool as we navigate the complexities of distributed systems, both now and in the future.